The term 'error' in the context of parameter fitting refers to the standard deviation of the distribution of experimental errors and may be used as an advanced data weighting method.
If user-defined errors are selected in the Fitting user interface as the data weighting method, the error values can be set or modified using the fourth row of the relevant data column (between the units and the start of the data) after clicking View Data.
Two types of errors can be set, absolute or relative. To set or edit a relative error, type in the percentage error in the cell, along with the "%" symbol (e.g. 2%). For absolute errors, type in the magnitude of the experimental error in the same unit as the data (e.g. 0.05). The plot in View Data also shows the error bars on the data.
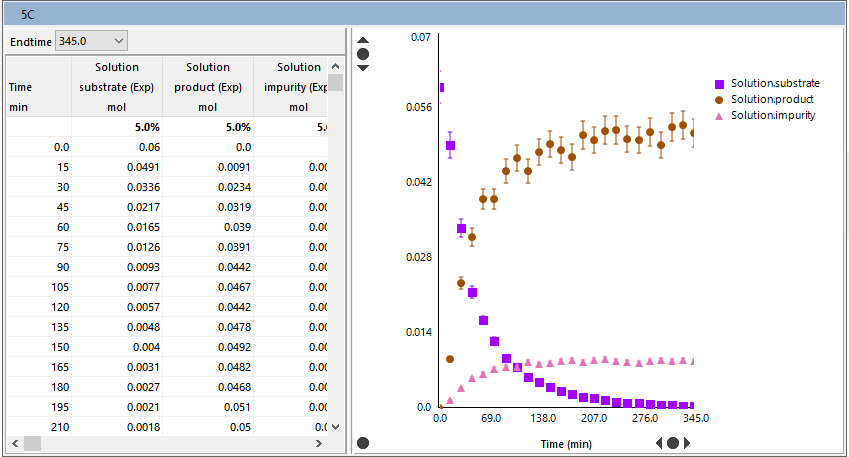
In this window you can also deselect individual or groups of data points.
When finished in this window, right-click in the title bar to close it.
Relative errors scale the size of the error with the value of the data point. Internally during fitting, absolute errors are used, calculated from the relative error and the value of the data point. For example if a species measurement is 2.3 mol, and a 1% error is selected, the (absolute value of the) error used in the fitting is 0.023 mol. Some caution is required if the data contains values very close to zero, as these will be assumed to have very small errors, which will tend to force the fit to go through these points, which is not always desirable. Any data points which have values of exactly zero are given absolute errors of 1.0, to avoid numerical problems.
New in Dynochem 5, if you type an error in the first data column of the first scenario to be used in Fitting, this error will be applied by default to all responses in all scenarios.
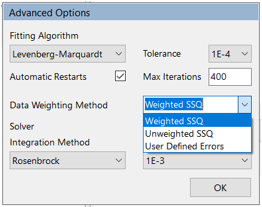
If user-defined errors are selected in the Fitting user interface as the data weighting method, if no errors were previously defined (e.g. in the Excel model), a relative error of 5.0% is assumed for all responses in all scenarios.